En 1950 el genial matemático inglés Alan Turing publicó un artículo titulado Computing Machinery and intelligence (Máquinas computadoras e inteligencia), iniciando la investigación en Inteligencia Artificial. Para Turing, hacia el año 2000 se comenzarían a construir máquinas capaces de superar el test, además de resolver creativamente teoremas matemáticos o jugar partidas de ajedrez.
Notas sobre Alan Turing
Estos últimos años estamos asistiendo a una auténtica revolución en todos los ámbitos de la vida, la irrupción de una tecnología que sin ser nueva ha sido reformulada y llevada a casi todos los ámbitos de la vida gracias a tres avances principales que se han producido en la última década (entre otros) como son la consolidación de las redes de comunicaciones a nivel mundial, el aumento de la capacidad de cálculo computacional paralelo y el desarrollo de paradigmas lógicos revolucionarios en el ámbito del procesamiento de los datos/información.
Sin embargo debemos remontarnos a la fecha de la foto que observamos abajo, tomada en el verano de 1956 en la Universidad Dartmouth College, Nuevo Hampshire (EE.UU.), ya que fue durante el año anterior (1955) que varios investigadores entre los que se encontraban McCarthy, Marvin Minsky, Nathaniel Rochester y Claude Shannon, prepararon el evento que definiría el término que todos conocemos hoy en día como “Inteligencia Artificial“. La propuesta sobre lo que se discutió en aquella reunión que duró aproximadamente entre 6 a 8 semanas fue la de trabajar sobre la conjetura para diseñar una máquina capaz de emular las capacidades del aprendizaje e inteligencia humanas a partir del lenguaje creando abstracciones y llegando a conclusiones lógicas por si mismas basadas en el autoaprendizaje.
Subrayar que son fuentes de la inteligencia artificial no solamente el desarrollo de software en si mismo sino además también disciplinas como la filosofía, la neurociencia, la lingüística entre otras, incluso la lógica matemática es un área imprescindible desde antes de la existencia de los ordenadores con sistemas lógicos deductivos puesto que gran parte de la Inteligencia Artificial se basa en algoritmos matemáticos probabilísticos.

Una pequeña cronología de la evolución del desarrollo de la lógica (Fuente Wikipedia):
- Cerca de 300 a.C. Aristóteles fue el primero en describir de manera estructurada un conjunto de reglas, silogismos, que describen una parte del funcionamiento de la mente humana y que, al seguirlas paso a paso, producen conclusiones racionales a partir de premisas dadas.
- En 250 a.C. Ctesibio de Alejandría construyó la primera máquina autocontrolada, un regulador del flujo de agua que actuaba modificando su comportamiento “racionalmente” (correctamente) pero claramente sin razonamiento.
- En 1315, Ramon Llull tuvo la idea de que el razonamiento podía ser efectuado de maneral artificial.
- En 1847 George Boole estableció la lógica proposicional (booleana), mucho más completa que los silogismos de Aristóteles, pero aún algo poco potente.
- En 1879 Gottlob Frege extiende la lógica booleana y obtiene la Lógica de primer orden la cual cuenta con un mayor poder de expresión y es utilizada universalmente en la actualidad.
- En 1903 Lee De Forest inventa el triodo, también llamado bulbo o válvula de vacío.
- En 1936 Alan Turing publicó un artículo de bastante repercusión sobre los “Números Calculables”, un artículo que estableció las bases teóricas para todas las ciencias de computación, y que puede considerarse el origen oficial de la informática teórica.
- En 1943 Warren McCulloch y Walter Pitts presentaron su modelo de neuronas artificiales, el cual se considera el primer trabajo del campo de inteligencia artificial, aun cuando todavía no existía el término.
- En 1951 William Shockley inventa el transistor de unión. El invento hizo posible una nueva generación de computadoras mucho más rápidas y pequeñas.
Fue a partir del trabajo de Frank Rosenblatt y su descubrimiento del perceptrón en 1957 que la IA pudo dar un salto de gigante en su concepción como herramienta de procesamiento lógico al desarrollar un modelo capaz de emular el procesamiento de información tal y como lo lleva a cabo el cerebro humano, nacía la primera “neurona artificial” que culminó con el desarrollo y construcción del hardware del perceptrón, el Mark I en 1960 (ver artículo de Claude Shannon). Este fue el primer ordenador que podía aprender habilidades nuevas a base de prueba y error utilizando un tipo de red neuronal (artificial) que simula el proceso de pensamiento humano.
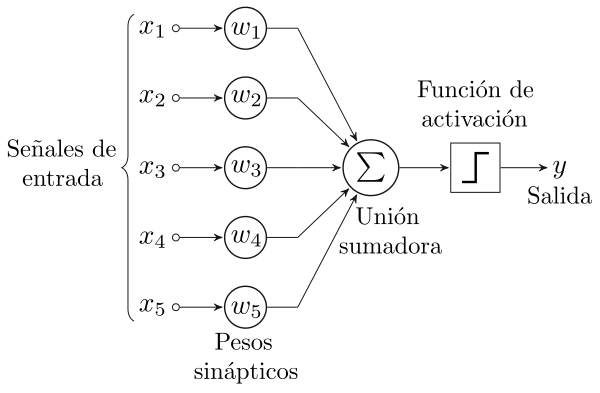
A partir de este modelo fue posible la evolución hacia otros modelos de redes neuronales mas evolucionados entre las que podemos distinguir según su arquitectura y función:
- Redes neuronales simples las que están compuestas por una sola capa de neuronas artificiales.
- Redes neuronales profundas están compuestas por varias capas de nodos que reciben entradas de otras capas y producen una salida hasta llegar a un resultado final. Las redes neuronales pueden tener cualquier número de capas ocultas: cuantas más capas de nodos tenga la red, mayor será su complejidad.
- Redes neuronales convolucionales (CNN) realizan funciones matemáticas específicas, como la síntesis o el filtrado, denominadas convoluciones. Son muy útiles para la clasificación de imágenes porque pueden extraer características relevantes de las imágenes que son útiles para el reconocimiento y la clasificación de imágenes.
- Redes neuronales recurrentes (RNN) son un tipo de red neuronal artificial que utiliza datos secuenciales o datos de series temporales. Estos algoritmos se usan comúnmente para problemas ordinarios como por ejemplo, la traducción de idiomas, el procesamiento del lenguaje natural (NLP), el reconocimiento de voz y los subtítulos de imágenes.
Sin embargo el modelo de procesamiento del perceptrón tenía limitaciones en sus inicios, la más notable de ellas fue su incapacidad para realizar operaciones complejas (como clasificar entre más de un elemento, por ejemplo, un perceptrón no podría realizar la clasificación entre un gato, un perro o un insecto), hubo que esperar al desarrollo de otro concepto y algoritmo, el de “Back Propagation” que esperaba resolver el problema de la clasificación de datos complejos, este se inspiró en la neuroplasticidad de nuestro cerebro, una cualidad neurobiológica que modifica la fuerza de las conexiones entre las neuronas según sea necesario. Campo ampliamente investigado por Marian Diamond, pionera en el área de anatomía dentro del campo de las neurociencias junto con Ramón y Cajal, padre de la neurociencia moderna a comienzos de siglo XX, descubridor de la arquitectura de la neurona y la sinapsis.

Hay que destacar que en la década de los 90 se realizaron avances significativos en el área del Aprendizaje Automático (Machine Learning) o la Mineria de datos con la aplicación de multitud de algoritmos matemáticos aplicados al campo de la Inteligencia Artificial.
Como decía al principio del artículo han habido tres avances imprescindibles en las ciencias de la computación como son la consolidación de las redes de datos de alta velocidad, el aumento exponencial de la capacidad de procesamiento en paralelo por procesadores cada vez mas eficientes y el desarrollo de modelos o paradigmas de software innovadores, se podría afirmar casi con total certeza que este último avance es el mas relevante de todos y ha supuesto que el desarrollo de la Inteligencia Artificial no caiga en un nuevo invierno tecnológico como ya sucediera anteriormente en los años 60 y 80 con estancamientos de décadas, me refiero concretamente a las publicaciones revolucionarias que supusieron los papers tanto de Ian Goodfellow en 2014 y sus Redes Generativas Antagónicas (GANs) como el de Shish Vaswani y su equipo en 2017 con la publicación de “Attention is all you need“.
Por una parte Ian Goodfellow propuso un tipo de arquitectura de procesamiento compuesta por dos redes, Discriminadora y Generadora, que podían ser utilizadas para mejorar el proceso de aprendizaje si ambas trabajaban en conjunto. Esta tecnología dio como resultado un avance significativo para tareas tales como pueden ser la identificación de imágenes o la generación de contenidos.
Poco después Shish Vaswani y su equipo revolucionaban el paradigma del aprendizaje con la publicación de su paper “Attention is all you need” en 2017, donde sentaron las bases de una nueva arquitectura de procesamiento de la información basada en Transformers, una tecnología que a diferencia de las redes neuronales, no procesa la información de manera secuencial (un dato tras otro como una cadena) sino que basa el procesamiento de la información en una estructura enteramente focalizada en mecanismos de atención, esto permite a modelos como los de Procesamiento del Lenguaje Natural (NLP) por ejemplo ponderar distintas partes de una secuencia de entrada de forma selectiva, mejorando así la comprensión y generación de textos de manera estructurada y contextualmente coherente al procesar la información no secuencialmente sino por fragmentos de texto al mismo tiempo (en paralelo).
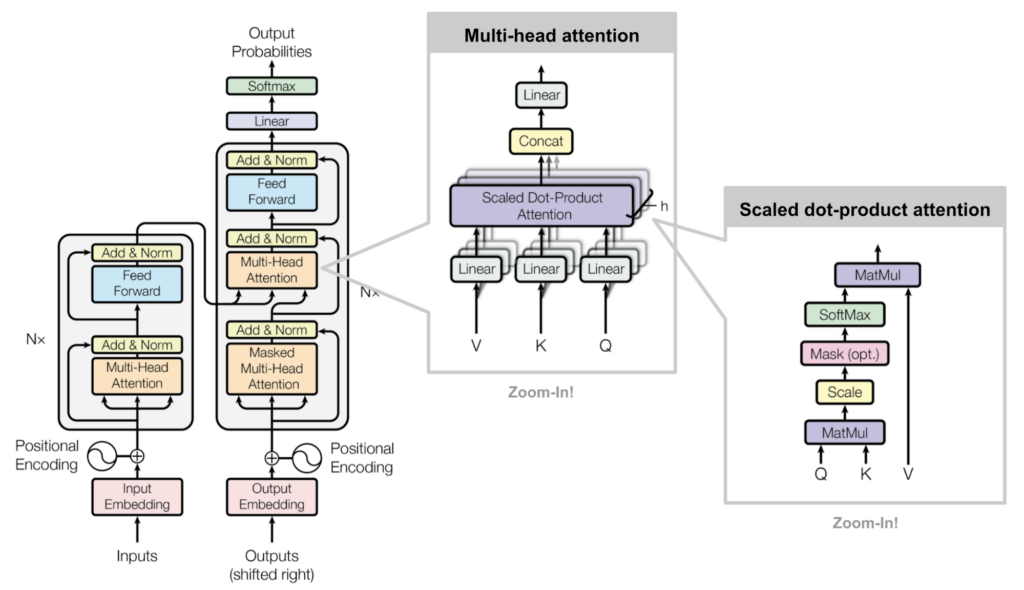
Esta tecnología (la mas avanzada ahora mismo) sobre la que trabaja el modelo Transformers nos ha traído grandes avances en el campo de la IA denominado NLP (Procesamiento Natural del Lenguaje) a través de aplicaciones como ChatGPT o Bard que han experimentado un creciente uso exponencial aplicado a múltiples áreas de la vida, industria, educación, creación de contenidos, etc para ello utiliza lo que se denomina “Atención de Cabezas Múltiples“, que permite al modelo poder gestionar diferentes segmentos de la entrada a la vez, proporcionando una mejor comprensión del contexto y la relación entre palabras. Este tipo de modelos es conocido como LLM (Large Language Models) que es la base tecnológica para los sistemas de Inteligencia Artificial Generativa. El problema de este tipo de tecnología es la gran cantidad de recursos que son necesarios para generar el modelo y mantenerlo en funcionamiento, pensemos por un momento en una grandísima enciclopedia que contiene millones de palabras y registros indexados accesibles a través de un algoritmo matemático, esto representa el uso y consumo de una grandísima cantidad tanto de espacio como de energía que ponen en duda su sostenibilidad.
FIN Parte I
RECURSOS
- Paper: Attention is all you need (pdf)
- Paper: Generative Adversarial Networks (pdf)
- Artículo: Tecnología Transformers explicada. Parte 1. Parte 2 (inglés)
No hay reseñas todavía. Sé el primero en escribir una.